


Fine-tuning Economics: ¿Cuánto cuesta adaptar un modelo de lenguaje?
En este análisis exploramos los costos y desafíos de modificar una LLM utilizando LoRA desde una perspectiva financiera. Desglosamos los factores clave que impactan el rendimiento y presupuesto.

Adaptar una LLM (Large Language Model) requiere una planificación detallada, especialmente cuando se trata de modelos no comerciales, es decir, aquellos que demandan más memoria de la que ofrece una laptop o computadora personal. Esta planificación puede abordarse en distintos niveles, pero, en general, implica considerar diversas etapas, desde la ingestión de datos hasta la validación y el despliegue final.
En este análisis, presentamos un enfoque de simulación para estimar el tiempo y costo de este proceso utilizando LoRA (Low-Rank Adaptation), dado que permite entrenar solo una fracción (10%) de los parámetros del modelo. Además, exploramos estrategias para reducir la carga computacional y realizamos tres análisis de sensibilidad para evaluar cómo diferentes factores impactan en la asignación de recursos.
Flujo de trabajo del Fine-Tuning

1. Recopilación y procesamiento de datos
Los datos se procesan en lotes (paquetes de datos), lo que permite que una instancia con CPU y 32 GB de RAM maneje eficientemente hasta 50 GB de datos sin cargarlos completamente en memoria. Este proceso está limitado por la velocidad de I/O, dependiendo del almacenamiento y la capacidad de la CPU.
2. Carga y configuración del modelo
El tiempo de carga del modelo se calcula en función de su tamaño (parámetros × bytes por parámetro) y un factor de sobrecarga asociado al optimizador y las activaciones. También se estima el número de GPUs necesarias según la memoria disponible.
📌 Ejemplo: Un modelo de 70B en FP16 (2 bytes por parámetro) pesa aproximadamente 140 GB. Con una tarjeta NVIDIA A100 (40 GB por GPU), serían necesarias entre 4 y 5 GPUs.
3. Fine-Tuning
El requerimiento computacional se estima en FLOPs considerando la longitud de la secuencia, el tamaño del batch y el número de pasos de entrenamiento. Dado que el escalado en GPUs no es perfecto, se emplea un modelo basado en la Ley de Amdahl para capturar la fracción no paralelizable.
Técnicas como Mixed Precision Training y otras optimizaciones pueden reducir el uso de memoria y acelerar el cómputo.
📌 Ejemplo: En nuestro modelo, el uso de FP16 junto con estas optimizaciones permite reducir el costo computacional hasta en un 20%.
4. Validación y evaluación
Esta fase tiene un costo computacional bajo, ya que suele ejecutarse en una sola GPU o incluso en CPU.
5. Despliegue
Optimización final del modelo, guardado de checkpoints y exportación para su implementación. Es una etapa rápida y utiliza predominantemente el CPU.
Recomendaciones de recursos
Nuestra simulación estima dinámicamente los recursos óptimos en función de las necesidades del modelo y los costos de GPU disponibles.

📌 Requerimientos de GPU:
Basado en el costo total y la eficiencia del entrenamiento, los resultados sugieren que la opción más rentable para el fine-tuning de un modelo de 70B parámetros en FP16 es la NVIDIA RTX 3090.
Costo total estimado: $230.6
Tiempo total de entrenamiento: 30.3 horas
Costo por hora: $7.6/h
Aunque la NVIDIA A100 es más rápida (23.2 horas), su costo por hora más alto ($14.1/h) hace que la RTX 3090 sea la opción más rentable en términos de costo total.
📌 Alternativas de GPU según la prioridad:
Si se prioriza costo total: RTX 3090 es la mejor opción.
Si se prioriza tiempo de entrenamiento: A100 (23.2 h) o V100 (33.0 h) pueden ser más adecuadas.
Si se busca un balance entre costo y velocidad: V100 ($394.5, 33.0 h, $12/h) ofrece un punto intermedio.
Análisis de sensibilidad
Para evaluar cómo pequeñas variaciones afectan el costo y el tiempo del fine-tuning, realizamos tres análisis de sensibilidad, variando dos parámetros en cada uno y utilizando como referencia la NVIDIA A100 como GPU base.
1. Tamaño del modelo vs. número de Pasos
A medida que aumentan el tamaño del modelo y el número de pasos de entrenamiento, el costo total escala de forma no lineal.


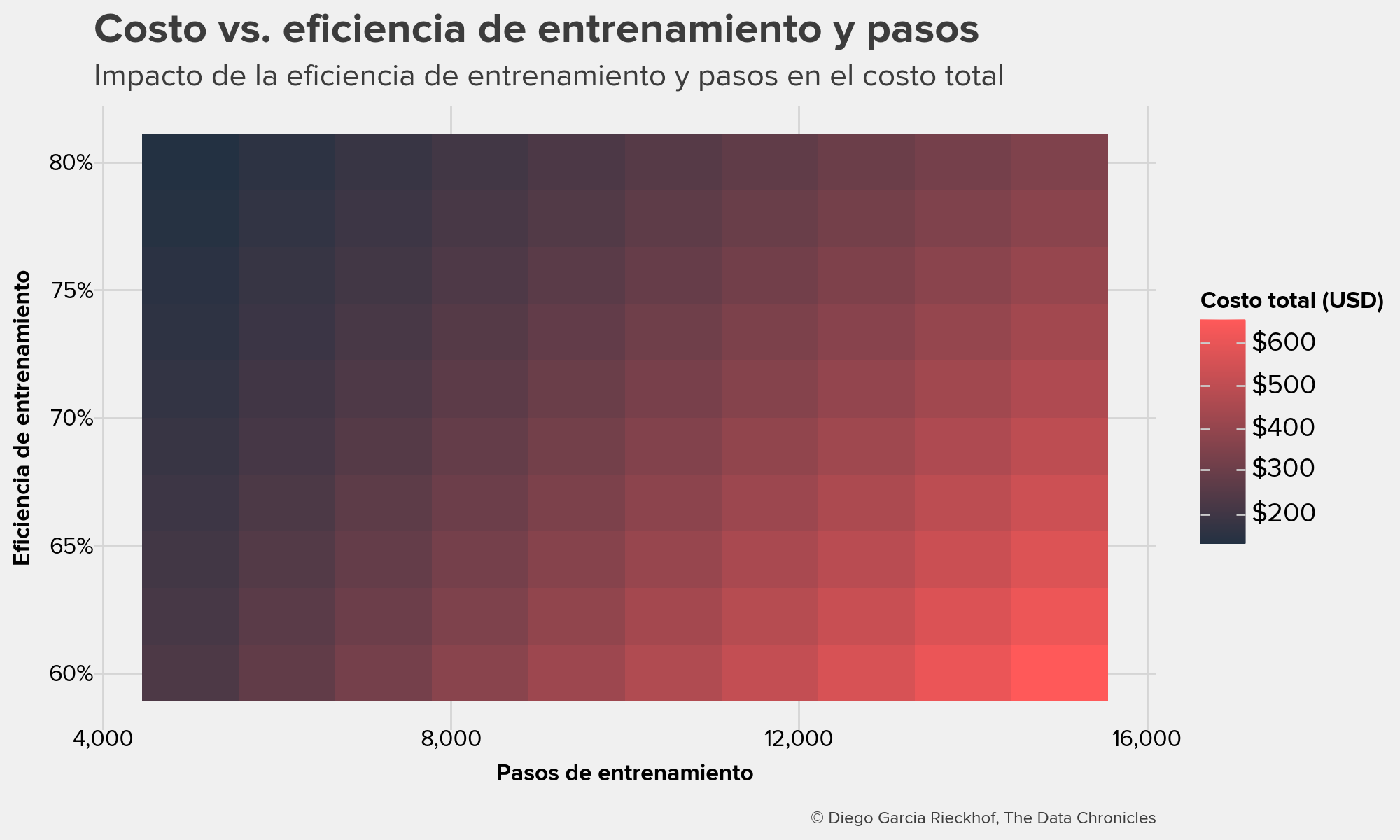
2. Eficiencia de entrenamiento vs. número de pasos
Si la eficiencia del entrenamiento disminuye o el número de pasos aumenta, el tiempo y costo del fine-tuning se disparan.

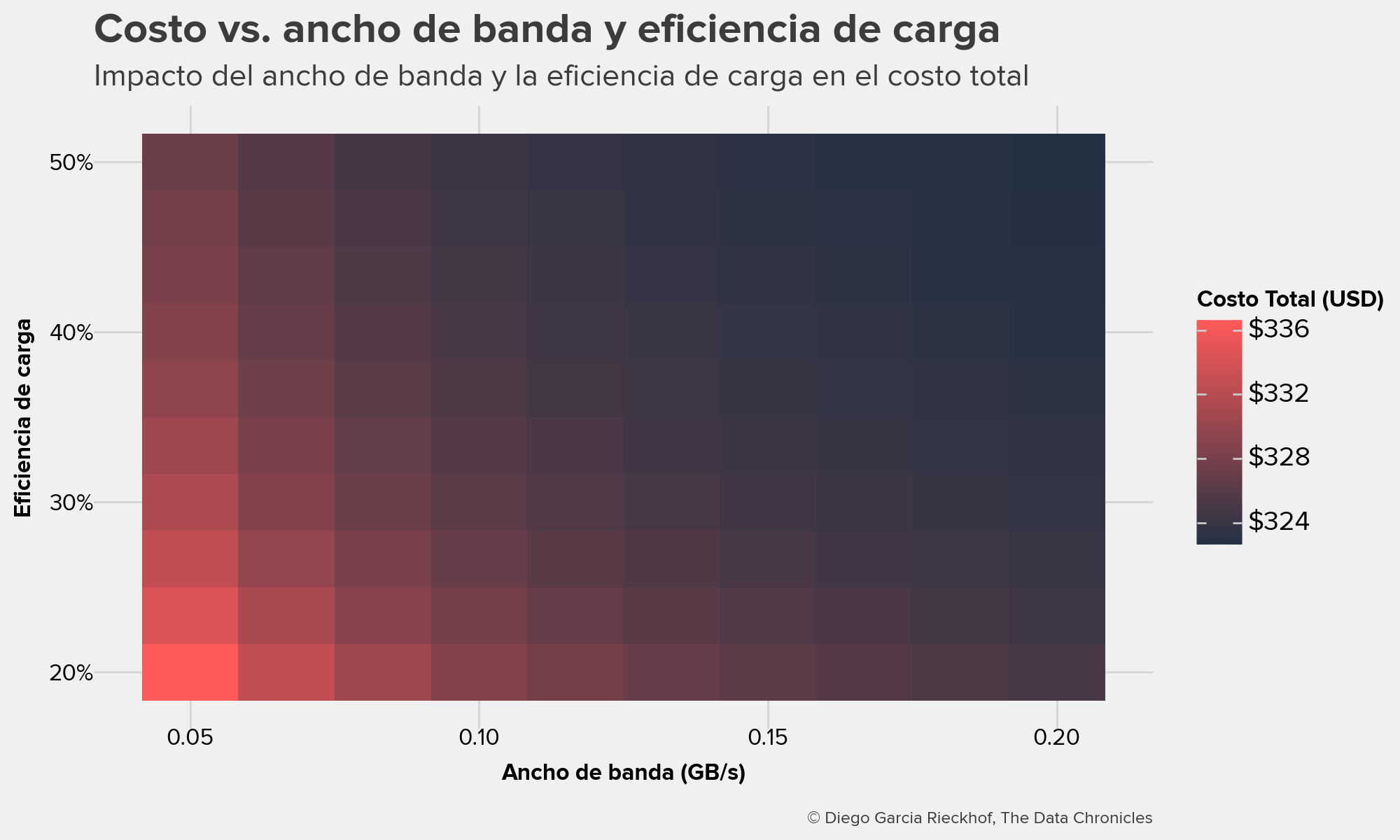
3. Ancho de banda vs. eficiencia de carga
Si el ancho de banda entre el disco y la GPU es bajo o la eficiencia de carga es reducida, el tiempo de carga del modelo se incrementa significativamente.

Conclusiones
El análisis demuestra que la planificación del fine-tuning de un modelo de 70B depende de múltiples factores clave:
✅ Ancho de banda de almacenamiento: Crucial para reducir los tiempos de carga del modelo.
✅ Eficiencia del entrenamiento: Impacta significativamente el costo total. Mejoras con precisión mixta y otras optimizaciones pueden generar ahorros sustanciales.
✅ Precisión del modelo y sobrecarga: El uso de FP16 reduce la demanda de GPUs y los costos asociados.
✅ Desempeño de la CPU: Aunque es menos costoso que las GPUs, su rendimiento puede afectar los tiempos generales del flujo de trabajo.
Este análisis permite tomar decisiones informadas para optimizar costos y rendimiento en el fine-tuning de modelos a gran escala.
📌 Si estás planificando un proyecto similar, te recomiendo realizar un costeo inicial para identificar puntos de mejora y optimizar recursos. Sin embargo, existen otros factores que pueden generar fricción durante el fine-tuning e incrementar los costos asociados. Aun así, este análisis proporcionará una visión más clara de los costos de infraestructura involucrados.